AlphaPoke: può un'IA imparare a giocare a Pokémon?

Per il corso di "Sistemi Intelligenti Avanzati" dell'Università degli Studi di Milano ho dovuto realizzare un progetto utilizzando tecniche di AI. Ho scelto di sfruttare questa opportunità per cercare di rispondere ad una semplice domanda: è possibile addestrare un'intelligenza artificiale per giocare a Pokémon in modo competitivo?
Disclamer: l'articolo sottostante vuole dare una spiegazione molto generica del progetto, senza perdersi in formalismi e formule troppo complesse. Per maggiori informazioni leggere il report o consultare il codice sorgente.
Il gioco
Il progetto è stato realizzato utilizzando le regole della Gen 8 di Pokémon (VGC 2020, VGC 2021, VGC 2022) ma considerando battaglie in singolo e non in doppio. Per quelli che non sanno quali siano le regole di Pokémon (mi dispiace) consiglio di leggere il secondo capitolo del report che ho realizzato per l'esame dove vengono spiegate sia le regole che il gameplay loop del gioco.

Uno screenshot di "Pokémon Spada/Scudo" Copyright © Nintendo
Il problema
In apparenza Pokémon non sembra un gioco particolarmente complesso:
- Ogni giocatore ha 6 Pokémon
- Ogni Pokémon ha 4 mosse
Non sono poche permutazioni ma non sembra così impossibile trovare la soluzione esatta. Quello che purtroppo spesso si ignora è che Pokémon è un gioco basato molto anche su componenti stocastiche (casuali, "randomiche") e dove si hanno informazioni incomplete (vedi terzo capitolo del report).
Variabili
6 Pokémon e 4 mosse per Pokémon. Non sono molte vero? Certo, se non si considera che ogni Pokémon è definito da:
- le sue statistiche di base (base stats)
6 valori per Pokémon - i suoi tipi
- la sua abilità
- il suo oggetto
- i sui boost alle statistiche
- le sue condizioni di stato
- le sue mosse
- le sue eventuali mega evoluzioni, mosse Z, gigamax
- i suoi IV ed EV
e che ogni mossa è definita da:
- la sua precisione
- la sua potenza
- il suo tipo
- quante volte colpisce
- eventuali effetti secondari
e che poi l'ambiente viene definito da:
- la sua condizione metereologica
- il suo campo
- le sue condizioni (Levitoroccia, Fielepunte, etc)
RNGesus

Ma quali componenti sono sotto il dominio di RNGesus? Praticamente tutte:
- Brutti colpi
- Precisione delle mosse
- Moltiplicatore dei danni (ogni mossa durante il calolo dei danni viene riscalata con un moltiplicatore tra 0.85 e 1)
- Effetti secondari delle mosse
- Mosse multi-hit (ad esempio Furia, Cadutamassi, etc.)
Tutto questo rende calcolare la policy ottima (per i non addetti ai lavori: una policy specifica quale azione l'agente deve eseguire quando si trova in uno specifico stato) estremamente complesso dato che un'azione applicata diverse volte allo stesso stato porta a stati successivi differenti.
Informazioni
Come se non bastasse, Pokémon è un gioco a informazione incompleta. Questo significa che un agente deve decidere quale azione compiere senza conoscere completamente l'ambiente in cui si trova (esempio ovvio: i Pokémon dell'avversario ed i relativi moveset).
Primo approccio: Q-Learning
I primi tentativi di apprendimento con rinforzo non si basano su reti neurali, bensì su enormi tabelle stato-azione e sull'assunzione che il gioco sia un processo markoviano (Pokémon la rispetta). Sono tanti termini: andiamo con calma.
Un processo markoviano è un sistema dinamico in cui le probabilità delle transizioni da uno stato all'altro dipendono solo da quello immediatamente precedente e non da come si è arrivati a quello stato (esempio semplice: non importa se sono arrivato in uno stato usando Rafforzatore 2 volte o Ferroscudo una volta, le probabilità di transizione a seguito di una mossa superefficace da un Pokémon avversario appena entrato in campo sono le stesse).
L'apprendimento con rinforzo è uno dei 3 paradigmi principali dell'apprendimento automatico, nello specifico questo su occupa di problemi di decisioni sequenziali. Il principio alla base dell'apprendimento con rinforzo è lo stesso che ci permette di installare un riflesso condizionato in un animale (vedi gli esperimenti sui cani di Ivan Pavlov): l'agente riceve un premio per ogni scelta corretta e una punizione per ogni scelta errata (la ricompensa).
L'obiettivo degli algoritmi di Q-Learning è stimare
Apprendimento on-policy: SARSA
L'algoritmo di apprendimento SARSA (stato-azione-ricompensa-stato-azione) stima i valori
dove
Ma
E se due azioni hanno lo stesso valore? Questa è una scelta implementativa: ne si può scegliere una a caso, si può prendere la prima per indice, etc. L'importante è essere consistenti.
E come fa ad imparare se sceglie sempre la prima azione che gli fornisce una ricompensa?
Questo problema è descritto dagli addetti ai lavori come il binomio exploration-exploitation.
L'esplorazione (exploration) dovrebbe essere prevalente all'inizio dell'addestramento, quando non si conosce ancora nulla dell'ambiente.
Lo sfruttamento (exploitation), invece, dovrebbe essere prevalente (ma non l'unico presente) alla fine dell'addestramento, quando l'ambiente è conosciuto.
Spesso si usa una policy chiamata
Apprendimento off-policy: Q-Learning
L'algoritmo di Q-Learning è molto simile a SARSA. L'unica differenza si trova nel calcolo delle ricompense future attese:
Come si vede dalla formula, infatti, il calcolo delle ricompense future in SARSA viene eseguito direttamente sulla policy appresa
Struttura dell'apprendimento
In generale uno step di addestramento di un agente tramite questo primo approccio segue questa scaletta (dopo un primo passo di inizializzazione):
- L'agente riceve lo stato corrente
- L'agente sceglie con la sua policy appresa
(che bilancia con un qualche meccanismo exploration ed exploitation) l'azione da compiere - L'agente esegue l'azione scelta
e riceve la ricompensa e il nuovo stato dell'ambiente - L'agente aggiorna la sua stima di
- L'agente aggiorna lo stato corrente
È possibile dimostrare che questi algoritmi garantiscono di ottenere in tempo finito
Limitazioni di questo approccio
La più grande limitazione di questo approccio è anche la più intuitiva: con un ambiente altamente variabile, il numero di stati risulta essere esponenziale. Questo impedisce all'agente di riconoscere stati uguali tra di loro se non per una singola variabile e provoca un'esplosione della tabella stato-azione della policy.
Secondo approccio: DQN (Deep Q-Learning)
Per superare il limite delle tabelle stato-azione sono arrivate in soccorso le reti neurali.
Queste, emulando il funzionamento dei neuroni nel nostro cervello, sono in grado di generalizzare gli stati simili: forniscono una stima dei valori di
Praticamente
Ma praticamente cosa succede? Nonostante tutti i paroloni che noi informatici possiamo inventarci per sembrare degli stregoni elfici mentre lanciano una magia in draconico, il DQN funziona come il Q-Learning ma sostituisce la tabella stato-azione con una rete neurale:
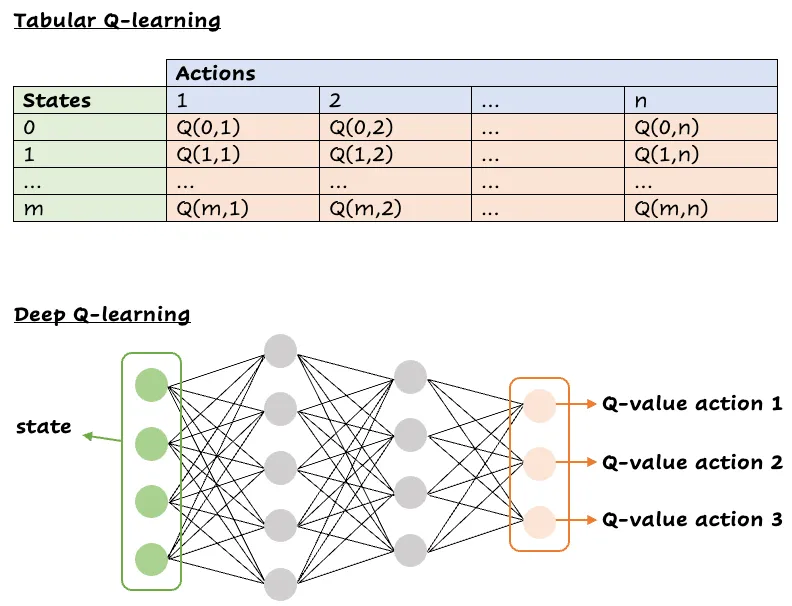
Paragone tra una tabella stato-azione (in alto) e una rete neurale per il DQN (in basso)
Tutti gli step di addestramento sono mantenuti:
- L'agente riceve lo stato corrente
- L'agente sceglie con la sua policy appresa
(che usa la rete neurale per stimare i valori di ) l'azione da compiere - L'agente esegue l'azione scelta
e riceve la ricompensa e il nuovo stato dell'ambiente - L'agente aggiorna la sua stima di
aggiornando la rete neurale (questa è la parte difficile dove effettivamente ci piace tirar fuori un po' di paroloni come discesa del gradiente, funzione di attivazione, bias, regolarizzazione dei pesi, etc.) - L'agente aggiorna lo stato corrente
Risultati sperimentali
Ma quindi funziona? Per poter rispondere a questa domanda serve innanzitutto sapere cosa è stato addestrato.
Agenti addestrati
Sono stati addestrati due agenti: uno utilizzando solo un algoritmo di Q-Learning con una tabella stato-azione e uno attraverso l'algoritmo di DQN.
Spazio delle azioni
Lo spazio delle azioni rappresenta quali azioni l'agente può tentare di compiere in ogni stato ed è lo stesso per entrambi gli agenti.
Rappresenta l'insieme massimo ottenibile (non tutte le azioni sono disponibili in ogni stato ed in tal caso si restituirà all'agente una ricompensa di
- Usa la
-esima mossa - Usa la
-esima mossa come mossa Z - Megaevolvi il Pokémon e usa la
-esima mossa - Dynamaxa il Pokémon e usa la
-esima mossa - Scambia il Pokémon corrente con quello nello zaino in posizione
-esima
In totale sono possibili al massimo 21 mosse.
Spazio degli stati
Lo spazio degli stati rappresenta il formato in cui l'ambiente viene codificato per essere poi inviato all'agente.
Disclamer: dato che entrambi gli agenti sarebbero stati addestrati nel contesto di un progetto universitario sono state operate scelte volte a ridurre il carico computazionale in modo da poter essere addestrati su un server dalle risorse molto povere. Sono consapevole del fatto che siano estremamente sub-ottimali.
Q-Learning
Per limitare la dimensione massima della tabella stato-azione si utilizza una singola serie di valori:
- Un intero compreso tra -2 e 2 che rappresenta l'equilibrio tra le statistiche base del Pokémon dell'agente e dell'avversario
- Un intero compreso tra -1 e 1 che rappresenta l'equilibrio tra i tipi del Pokémon dell'agente e dell'avversario
- Un intero compreso tra -1 e 1 che rappresenta l'equilibrio tra i boost alle statistiche del Pokémon dell'agente e di quello dell'avversario
- Un flag che indica se il Pokémon dell'agente è dynamaxato
- Un flag che indica se l'agente deve mandare in campo un altro Pokémon (forced switch)
- Quattro interi tra -7 e 3 che rappresentano il valore delle mosse nel contesto della battaglia basati sul tipo della mossa, la sua potenza ed i boost alle statistiche
DQN
La rete neurale prende in input una codifica (encoding) dello stato. In particolare un vettore di valori numerici. Per evitare di introdurre ordinamenti indesiderati si utilizza la tecnica del one-hot encoding.
In che senso ordinamenti indesiderati? Prendiamo per esempio una codifica che trasforma i tipi di un Pokémon in una coppia di interi. Questo potrebbe indurre la rete a pensare che ci sia una qualche gerarchia dei tipi basata sul valore che la codifica assegna ad ogni tipo. Qusto problema viene evitato utilizzando un vettore di valori binari di lunghezza pari al numero di elementi che si fuole codificare e mettendo a 1 solo quello corretto (one-hot).
Rete neurale
Come già detto per quanto riguarda la tabella stato-azione, anche la rete neurale è stata dimensionata per essere gestita da un server con pochissime risorse. Di conseguenza verrà usato un solo layer nascosto con 1024 nodi. Il layer di output ha dimensione forzata (21 nodi, come la dimensione dello spazio delle azioni).
Addestramento
Entrambi gli agenti sono stati addestrati su migliaia di match simulati contro altri agenti che usano euristiche per ottenere risultati simili a giocatori neofiti di Pokémon (esempio: usare la mossa con potenza maggiore, indipendente dal tipo).
Risultati
Un primo risultato importante è che entrambi riescono ad ottenere un rapporto vittorie/giocate (winrate) maggiore del 50% contro agenti che scelgono azioni in modo completamente casuale. Questo significa che probabilmente avrebbero fatto un lavoro migliore di molti genitori quando, disperati, chiedevamo loro di battere Brock perché avevamo scelto Charmander e ci pesava il culo portarlo fino al 13 per fargli imparare Ferrartigli.
In secondo luogo si è provato a farli scontrare contro avversari umani sul server di Pokémon Showdown insieme ad agenti con euristiche più avanzate (Simple heuristics) e ad agenti che usano la mossa più potente (Max base power). Purtroppo in questo secondo caso i risultati sono molto meno incoraggianti (sia per gli agenti che per gli umani). I grafici seguenti mostrano il valore medio e il picco di elo (valore che rappresenta la "forza" di un giocatore in un determinato videogioco e usato per far scontrare giocatori di "bravura" simile) ottenuto da ogni agente durante il test (1000 patrite per agente).
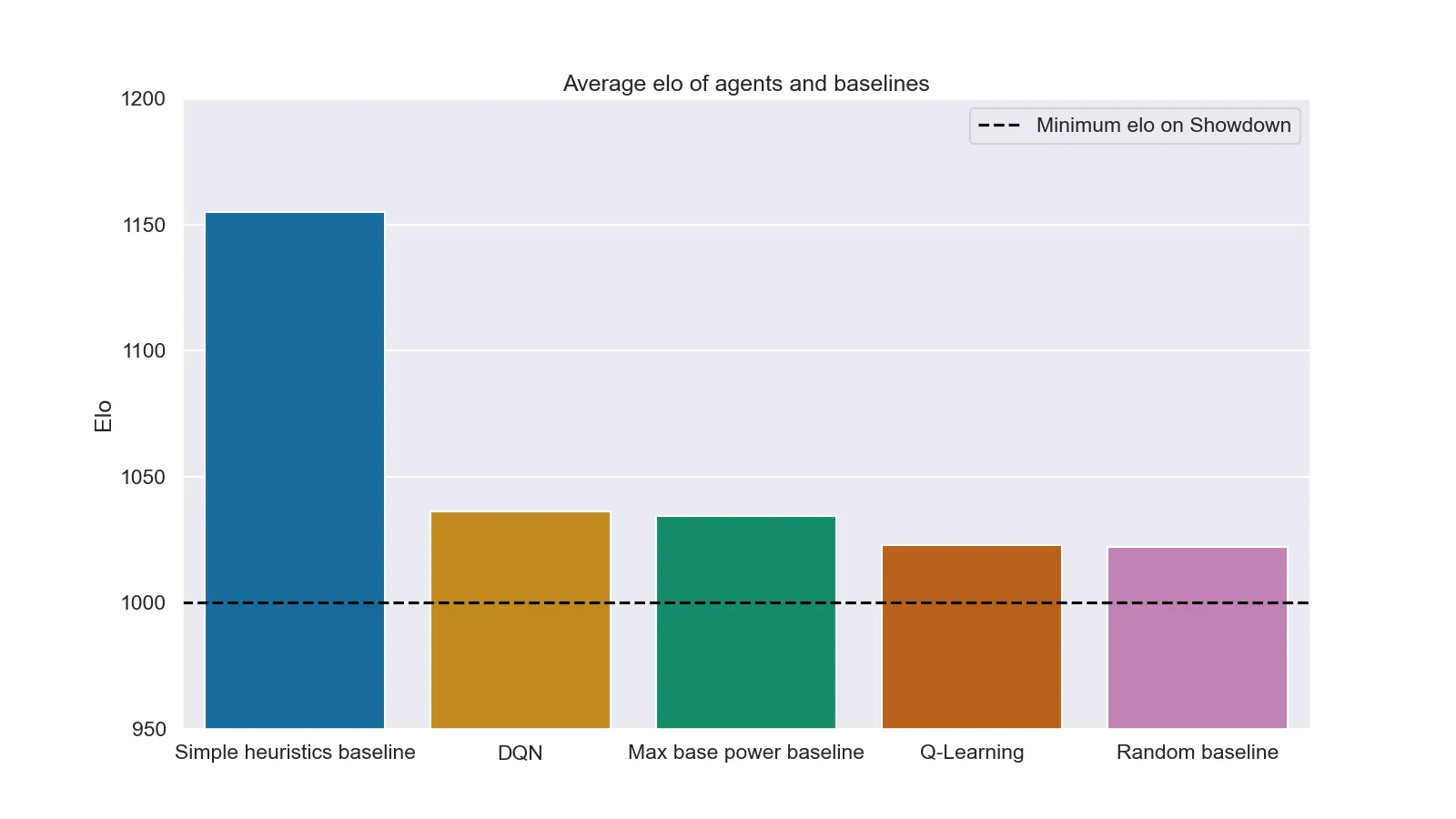
Elo medio raggiunto da ogni agente dopo 1000 partite
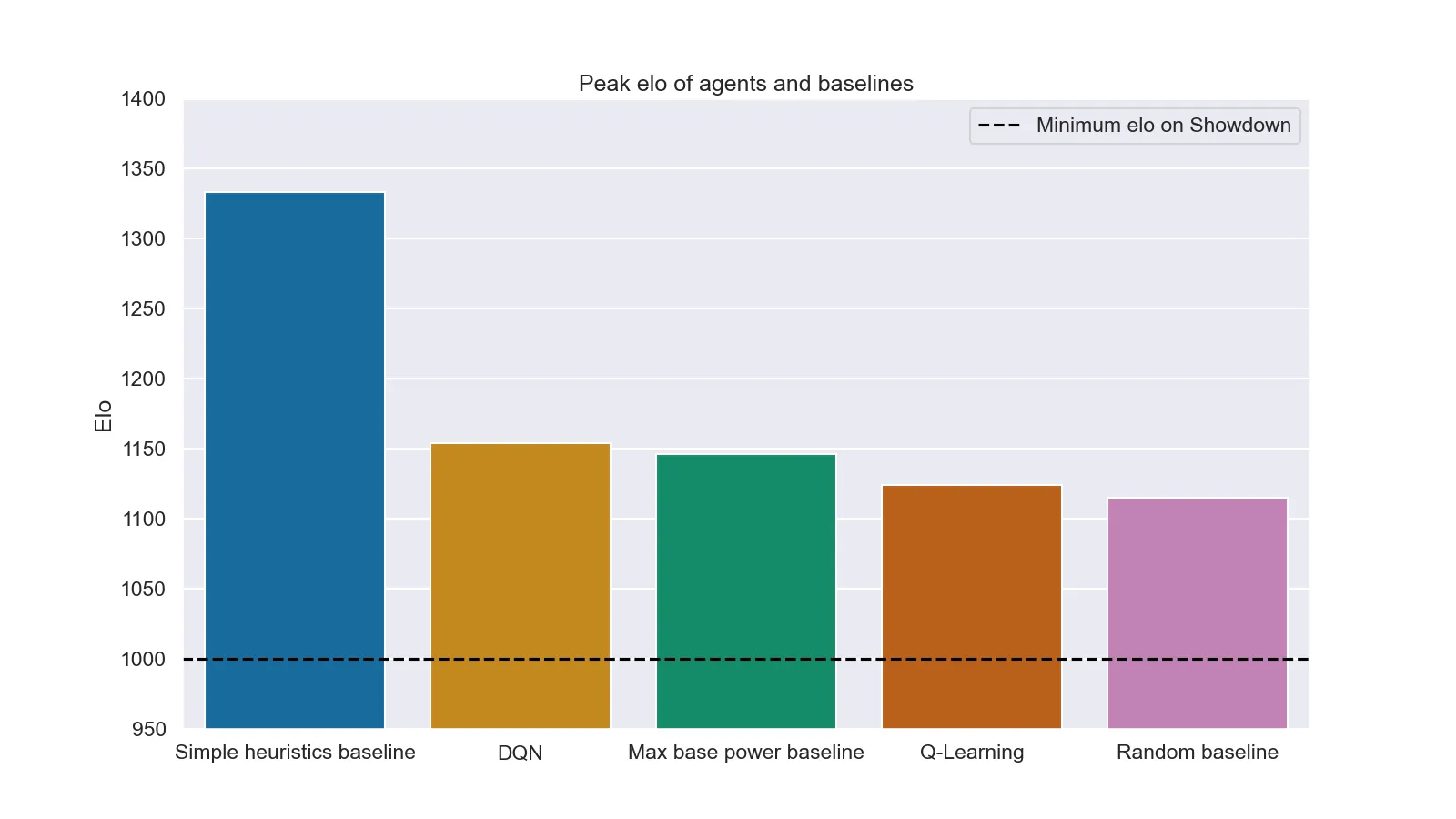
Elo massimo raggiunto da ogni agente dopo 1000 partite
È interessante notare come anche DQN non riesca a superare il risultato ottenuto da delle semplici euristiche (questo probabilmente a causa dell'eccessiva semplificazione della struttura della rete neurale. Con un server più potente sarebbe stato possibile testare architetture neurali più complesse portando con ogni probabilità ad un risultato diverso).
Un altro punto sicuramente interessante si ha nel risultato della baseline casuale: un elo massimo di circa 1125 indica che non poche persone sono riuscite a perdere contro un agente che letteralmente premeva tasti a caso.
Per un'ultima considerazione occorre un ultimo grafico: l'andamento dell'elo dei due agenti addestrati.
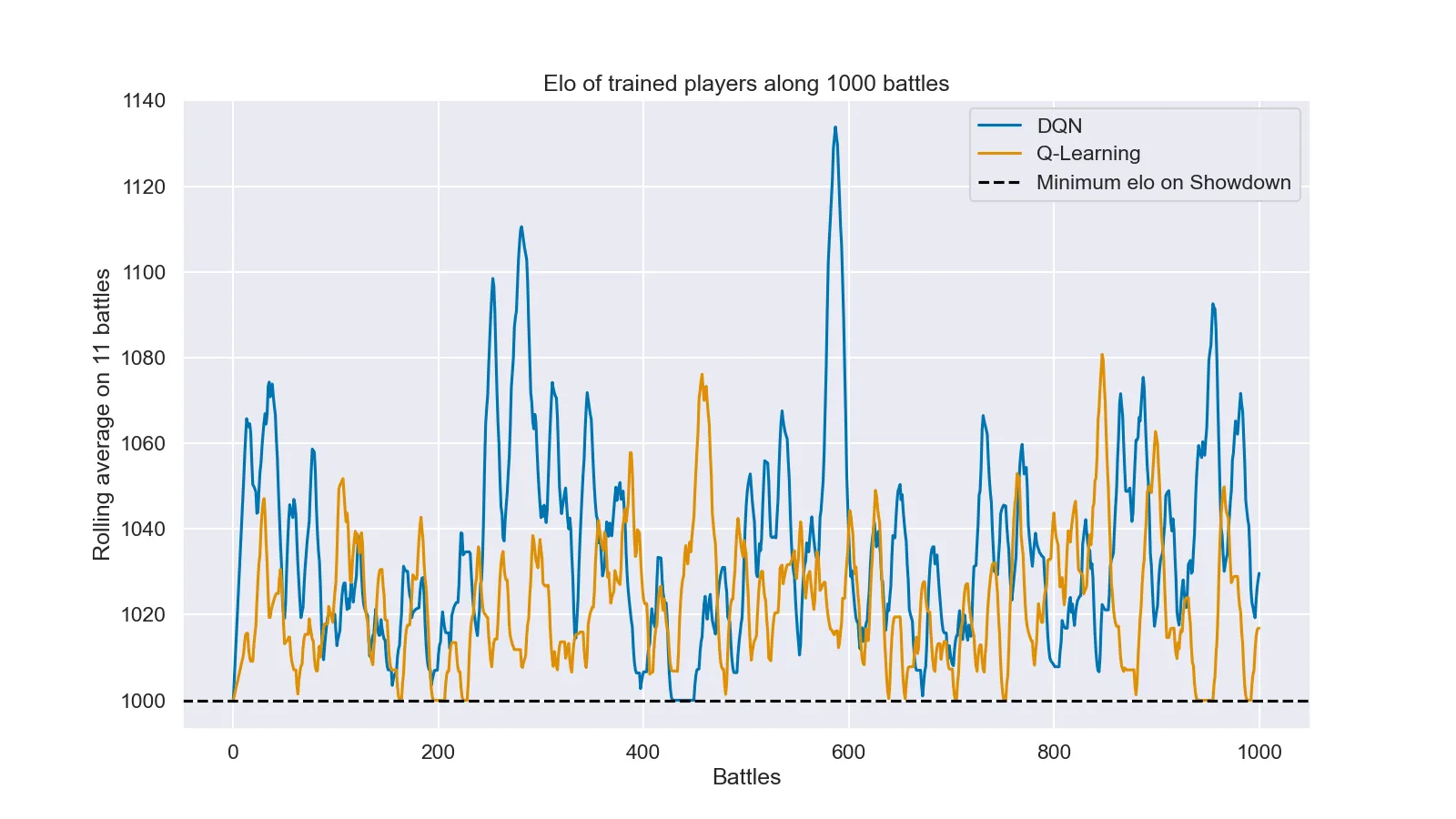
Andamento dell'elo dei due agenti addestrati durante 1000 partite
In questo grafico si può notare come nessuno dei due agenti addestrati in questo progetto sia riuscito a stabilizzarsi ad un elo superiore al minimo (1000), anche se dal grafico sembrerebbe che senza questa sicurezza l'agente DQN riuscirebbe a stabilizzarsi intorno a 1020, che è nulla ma comunque meglio dell'agente Q-Learning.
Posso provarli?
Certo. Puoi trovare eseguibili per diversi sistemi operativi qui. Ti basterà seguire le istruzioni scritte qui. Nel caso fossi curioso o volessi addestrare nuovi agenti partendo dai miei, trovi tutto il codice sorgente qui.